
1、使用覆盖索引
如果一条SQL语句,通过索引可以直接获取查询的结果,不再需要回表查询,就称这个索引为覆盖索引。
在MySQL数据库中使用explain关键字查看执行计划,如果extra这一列显示Using index,就表示这条SQL语句使用了覆盖索引。
让我们来对比一下使用了覆盖索引,性能会提升多少吧。
# 查看事务隔离级别 5.7.20 之后
show variables like 'transaction_isolation';
SELECT @@transaction_isolation
# 5.7.20 之后
SELECT @@tx_isolation
show variables like 'tx_isolation'
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ |
+---------------+-----------------+
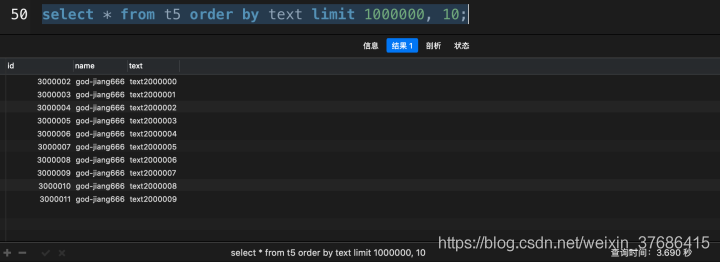
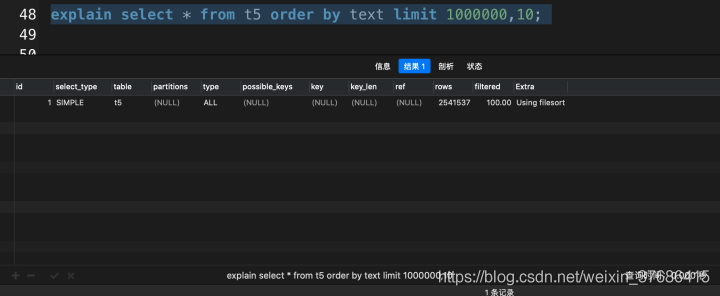
这次查询花了3.690秒,让我们看一下使用了覆盖索引优化会提升多少性能吧。
|
1
2
|
# 使用了覆盖索引select id, `text` from t5 order by text limit 1000000, 10; |
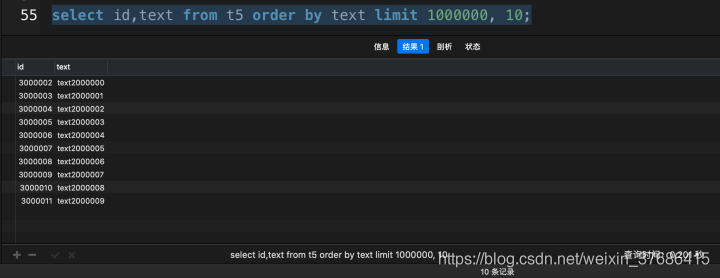
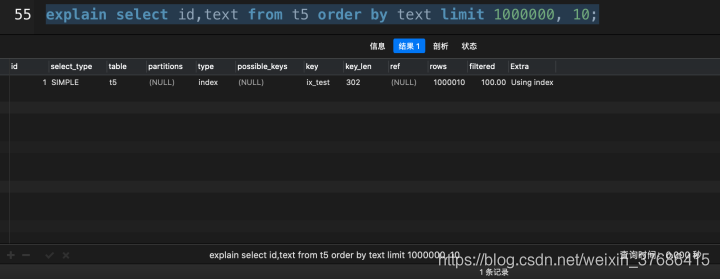
从上面的对比中,超大分页查询中,使用了覆盖索引之后,花了0.201秒,而没有使用覆盖索引花了3.690秒,提高了18倍多,这在实际开发中,就是一个大的性能优化了。(该数据在我的mbp上运行得出)
2、子查询优化
因为实际开发中,用SELECT查询一两列操作是非常少的,因此上述的覆盖索引的适用范围就比较有限。
所以我们可以通过把分页的SQL语句改写成子查询的方法获得性能上的提升。
|
1
|
select * from t5 where id>=(select id from t5 order by text limit 1000000, 1) limit 10; |
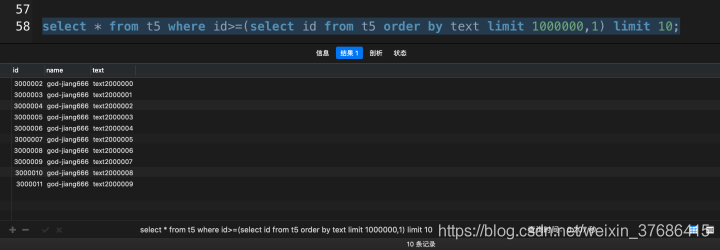
其实使用这种方法,提升的效率和上面使用了覆盖索引基本一致。
但是这种优化方法也有局限性:
- 这种写法,要求主键ID必须是连续的
- Where子句不允许再添加其他条件
3、延迟关联
和上述的子查询做法类似,我们可以使用JOIN,先在索引列上完成分页操作,然后再回表获取所需要的列。
|
1
|
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id; |
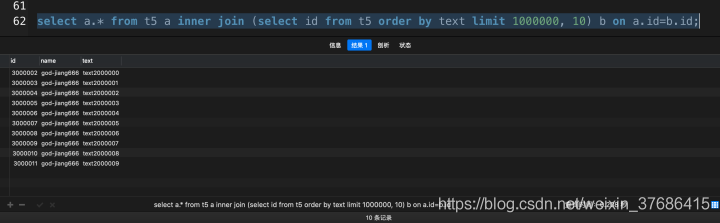
从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
4、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
|
1
|
select * from t5 where id>=1000000 limit 10; |
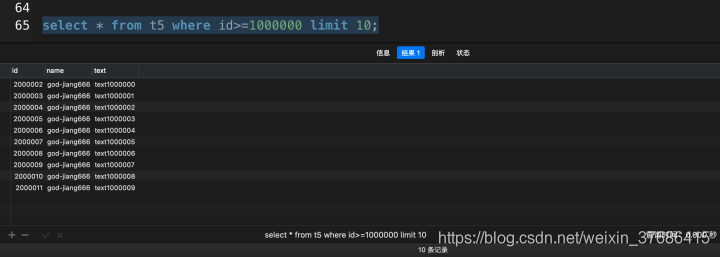
根据以上实验,不难得出,由于使用了主键索引做分页操作,SQL的性能是最快的。





